Recently, I started working with large Ad tracking data sets (billions and billions of records in each table). We want to perform analytics randomly over that data and we need all the columns across which analytics could be performed. I started thinking if I have to store them into a data warehouse what are my options.
Can I store tables (fact & dimensions) in the old school MSSQL data warehouse and create cubes? First, I ran a simple query “select count(*) from…” against one of the existing table in our corporate data warehouse that contains 82 millions rows and 8 columns. It took 8 minutes to get me the result. Second, I thought how many cubes will we have to create as the analytics will be performed randomly in several different ways. Due to poor performance and uncertainty in the ways analytics will be performed, I decided to try big data solution i.e. Redshift.
Redshift is Amazon Web Service’s MPP data warehouse solution. Here the MPP stands for Massively Parallel Processing. Below are the few things to note about MPP:
- Column Storage Technology: The data is stored column wise as opposed to row wise. It supports high compression and in-memory operations. These features give tremendous performance when you have to perform aggregation tasks.
- RDBMS: The database behind the scene stores the relational data.
- SQL: SQL is used as query language.
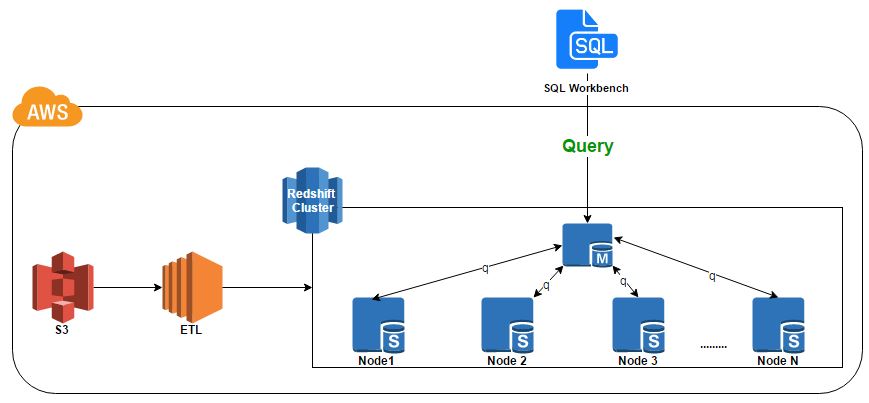
- Divide and Conquer: When a SQL query is executed then the query is first distributed among nodes. These nodes then get the results in parallel and a single consolidated result is presented.See diagram below for the reference architecture of the exercise.
- Huge Data set: The solution is useful for very large data sets.
The features distributed parallel processing, column storage, high compression and in memory operations instantly attracted me. I couldn’t resist myself to explore and experiment further.
So, I provisioned Redshift cluster with single node with lowest available node configuration (dc1-large) through AWS console. I created an ETL (console application using c#) to upload data set for one table. The data for this table was stored in several .csv files and resided in S3 bucket. I used Redshift’s COPY command. COPY command is one of the most efficient way to upload data in Redshift. It took approximately 2 hours to upload 250 million rows across 102 columns in the table. That’s amazingly great performance using single node.
As I have data in the data warehouse, it was time to run a basic query “select count(*) from…”. I used SQL workbench to run queries. Before I blinked my eyes, the result was there. It took less than 2 sec to generate the count. It was super fast.
Now, its time to run a query that does some aggregations. I created a query with ‘group by’ on few columns and aggregated a measurable column (Count). Then I ran the query. The result appeared in 5m 3s. Remember, I provisioned cluster with single node. The result was fast but I was not satisfied with the timing.
Amazon claims that the performance will be 2x faster if provisioned with 2 nodes. It was time to see MPP in action. I changed the number of nodes to 2. Then I ran the same query. Guess what, Amazon’s claim was right. I got result in 2m 27s. That’s spectacular.
What if I provision with 4 nodes. Would the performance be 4x faster? And yes, it was. It took 1m 21s to generate the same exact result from the same exact query. Mind blowing.
AWS Advantages:
It was so easy to provision nodes and use MPP service provided by AWS. From economy of scale point of view, we can provision more resources whenever we need with pay as you go basis. AWS charges $0.25 per hour per node. Here is the pricing link.
Competitors:
There are several alternatives available in the market but, in my opinion Microsoft Azure- SQL data warehouse is similar cloud based option available in this space. You might want to consider another emerging option which is Google Big Query.
Finally, I was amazed with the performance and the way I was able to use power of MPP easily and economically through AWS. At last, I want to mention, if you are more into performing row based operations (straight select * from) instead aggregations and not working with huge data sets then Redshift is not the solution for you.
